基于Azure搭建PredictionIO和Spark的软件开发成果——推荐引擎服务
- 2016-08-26 16:17:47
-
1. 在Azure构建Ubuntu 16.04虚拟机
假设前提条件您已有 Azure 帐号,登陆 Azure https://portal.azure.com 。
点击左上部的 +New 按钮,在搜索框中输入 Ubuntu ,或者点击 Virtual Machine 选择 Ubuntu Server 14.04 LTS,然后点击 Create 创建虚拟机。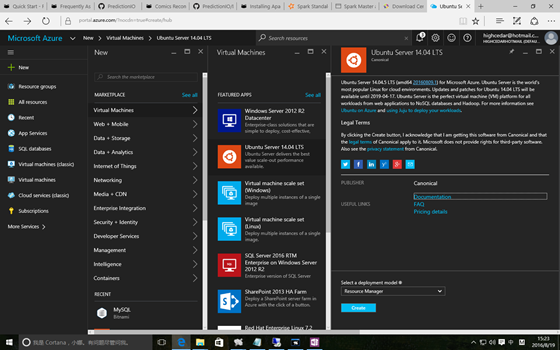
创建完成虚拟机后,在虚拟机的设置中找到 Azure 为其分配的 IP 地址,通过 Bitvise SSH Client 远程登陆虚拟机开始快速搭建推荐引擎服务之旅。
2. 以 PredictionIO 源码编译的方式安装
之所以本文以源码编译的方式安装 PredictionIO ,是因为其他方式我都未尝试成功。
2.1 编译
Run the following to download and build Apache PredictionIO (incubating) from its source code.
- 2
- 3
- 4
You should see something like the following when it finishes building successfully.
… PredictionIO-0.9.6/sbt/sbt PredictionIO-0.9.6/conf/ PredictionIO-0.9.6/conf/pio-env.sh PredictionIO binary distribution created at PredictionIO-0.9.6.tar.gz Extract the binary distribution you have just built.
2.2 安装依赖
Let us install dependencies inside a subdirectory of the Apache PredictionIO (incubating) installation. By following this convention, you can use Apache PredictionIO (incubating)’s default configuration as is.
2.3 安装Spark依赖包
Apache Spark is the default processing engine for PredictionIO. Download and extract it.
- 2
If you decide to install Apache Spark to another location, you must edit PredictionIO-0.9.6/conf/pio-env.sh and change the SPARK_HOME variable to point to your own Apache Spark installation.
2.4 数据存储
官方给的例子是采用 PostgreSQL 或者Hbase + Elasticsearch,我选择 MySQL 作为数据存储,因为在将来的数据可视化方面会采用 Caravel 自动化生成仪表板展现数据,在后续的文章中我会再详细介绍这方面。
在mysql官方网站下载 mysql-connector-java-5.1.37.jar 并保存至 PredictionIO-0.9.6/lib 文件夹中。 修改pi配置文件 pio-env.sh
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
2.5声明 PrecidtionIO 和 Java 的环境变量
我是在 /root/.bahsrc 里增加如下代码:
- 2
- 3
- 4
- 5
- 6
- 7
3. 创建推荐引擎服务
3.1 启动 PredictionIO Event Server
因为我在运行 PredictionIO 过程中发现它还是挺吃内存的,不管是 PredictionIO 还是 Spark,因此我特别分配的16的内存运行 Event server
3.2 启动 Spark
通过 PredictionIO 内置的脚本启动 Spark 进行模型训练时总是出现问题,所以采用手动启动 Spark 集群的方式规避此问题。
You can start a standalone master server by executing:
Once started, the master will print out a spark://HOST:PORT URL for itself, which you can use to connect workers to it, or pass as the “master” argument to SparkContext. You can also find this URL on the master’s web UI, which is http://localhost:8080 by default. Similarly, you can start one or more workers and connect them to the master via:
即
Once you have started a worker, look at the master’s web UI (http://localhost:8080 by default). You should see the new node listed there, along with its number of CPUs and memory (minus one gigabyte left for the OS).
3.3 Create a new Engine from an Engine Template
Now let’s create a new engine called MyRecommendation by downloading the Recommendation Engine Template. Go to a directory where you want to put your engine and run the following:
- 2
A new directory MyRecommendation is created, where you can find the downloaded engine template.
3.4 Generate an App ID and Access Key
You will need to create a new App in PredictionIO to store all the data of your app. The data collected will be used for machine learning modeling. Let’s assume you want to use this engine in an application named “MyApp1”. Run the following to create a new app “MyApp1”:
You should find the following in the console output:
… [INFO] [App
]InitializedEventStoreforthisappID:1.[INFO][Ap返回首页] [打印] [返回上页] 下一篇
