软件外包服务器系统架构设计案例
- 2016-02-19 09:50:28
-
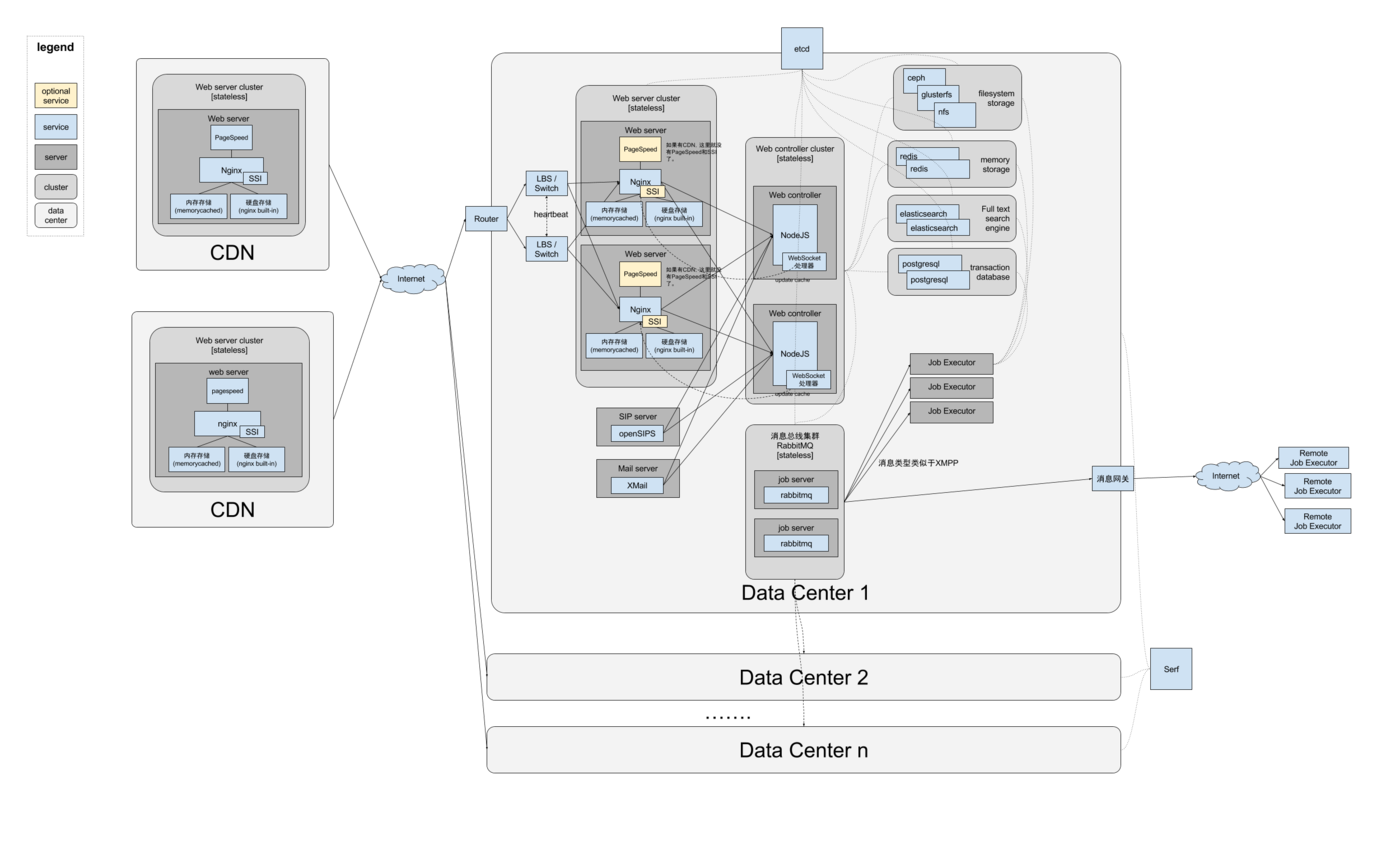
服务端系统拓扑结构图
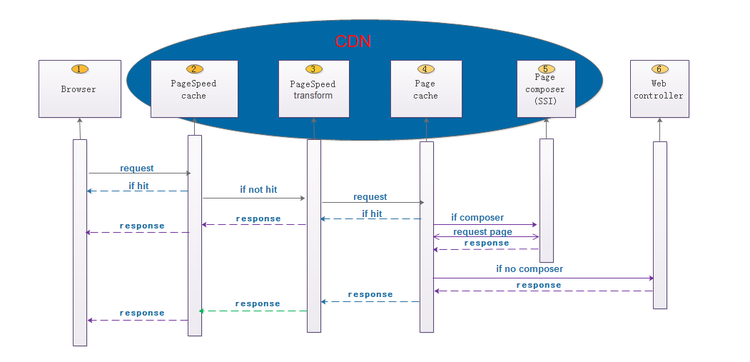
1. CDN友好的静态化:
传统CDN只缓冲静态资源,例如图片,JS,CSS等很久不变的内容。对于数据库动态创建的内容而言,使用CDN缓冲,性能还会有所下降。WWARE的缓冲机制改变了这一点,CDN可以缓冲所有的内容——无论静态内容还是动态内容。
WWARE默认的缓冲机制是,所有Web controller创建的内容,默认具有长生命周期,只有内容依赖的资源变动时,由Web controller刷新除Browser层之外的缓冲。这允许我们静态化全部内容,极大提升缓冲性能,非常适合于内容刷新周期慢的应用场合——例如商品详情,一次更新,很久不会变化。在其不变的时间内,其内容被当做普通页面被CDN分发,这将会极大提升用户体验。
对于频繁刷新的内容,例如聊天。可以关闭其缓冲特性,则默认客户端会自 动通过api.YOURDOMAIN来绕开CDN。WWARE正在支持运行期的频度检查,如果检查到更新频度过快,会自动临时关闭CDN缓冲。这个特性尚未支持完毕,目前需要手动指明是否绕开CDN。
2. 碎片化缓冲
传统的页面拼装发生在逻辑层,这导致缓冲内容必须以页面为单位,极大的降低了缓冲效能。WWARE的缓冲以小于页面的逻辑块为单位,通过将页面拼装前移到CDN层来极大的提升缓冲性能。例如,一个页面,如果只有右上角一个小块(DIV)是用户信息,构成其它内容的块都属于公共信息。则每次组装只需要请求最小的右上角的块,其它块都从位于CDN的缓冲中获取,极大的提升了访问速度。
3. 浏览器级优化
由于不同浏览器支持的特性不同,对不同资源的处理性能也不尽相同。在CDN的最前端,会根据UA信息,构建浏览器的特性表。根据这个特性表,再对内容执行一次最终的优化——完全针对浏览器级的优化,并缓冲起来,为下次相同特性的浏览器直接返回。这会最大化利用访问者的浏览器能力。
我们会在用户浏览器上执行wwclass.min.js。这个文件作为集群控制的最前端,执行如下任务:
1. 根据当前视口信息,决定加载顺序。换言之,除了主文件,其它资源只有必要的才会被直接加载。这显著降低了从DOMContentLoaded到load之间所需加载的资源。极大的提升了用户体验。所有非直接显示的资源,会被延迟加载,而这个延迟,访问者是体会不到的,只能感觉到页面加载速度很快。
2. 定义了客户端的VV模型。整个wware以MVVCP模型构建,其中,浏览器支持了VV两层,而WWARE编译器支持了MP两层,C由人工输入业务逻辑,WWARE编译器产生最终代码。现在,客户端的数据绑定(DATA-BINDING)在knockoutjs库的基础上构建。
3. 维护客户端的双向通道。WWARE支持websocket(当前版本尚未兼容旧的commet协议)。在websocket基础上,使用stomp协议来执行双向通信。
4. 执行客户端的容错。当检查到部分服务器失效时,自动寻找下一服务器。对于使用heart-beat切换服务器的机制是一个补充。但是在分布系统下,其扮演了分发中心的角色。
5. 执行客户端组装,以最大化利用所有数据集群的能力。例如,一个页面中,频繁更新的用户数据部分从controller直接获取,而其它内容从CDN获取,在客户端组装在一起。您注意到某些页面,显示出来之后,会有部分内容转圈,并显示加载中,就是这个部件在工作。
5. 在多数据中心下,通过gossip协议来协商服务器处理的目标地址,对不同请求切换其URL前缀。用于客户端驱动的容错以及分布。这个特性取消了中央热点,使得系统处理上限完全并彻底的消失。无论是百亿、千亿乃至万亿的并发,只要多加数据中心就可以支持了。因为,不同用户被自动分发到不同数据中心。现阶段,wware的自动编译分配的分布单元,只能处理像网上订票这样的简单依赖,将其拆分为如不同数据中心处理不同车次的分布策略;对于复杂依赖,依然需要人工介入,人工制定分布策略。
1. HTTP/HTTPS
2.SPDY
3. HTTP2
4.WEBSOCKET
5.SMTP
6.POP3
7.SIP
8.DNS
WWARE不仅仅是一个WEB服务器,它是一个综合的业务逻辑处理中心。所有被支持协议的接入可以被controller所控制,并以web页面作为主要人机界面。 WWARE支持websocket,并可以在多个数据中心之间自由寻址。这极大的扩张了传统WEB应用的RR(Request-Response)模型,允许服务器任意时刻主动通知客户端。使用WWARE的应用,页面上是不应该出现刷新按钮的——服务器可以在需要时自动刷新。
WWARE支持SPDY以及HTTP2,这将急剧降低HTTP与HTTPS之间的性能差异。在不降低用户体验的情况下,可以大幅提升网站安全性,并提升访问者的信任。让我们一起拥抱安全的HTTPS时代吧。
四、服务器说明
1. 全异步模型:
在wware选择的支撑环境里,所有的服务器都支持全异步模型。这将大幅降低对系统资源的消耗,提升响应效率。但是书写逻辑代码不需要考虑异步——只需要以同步方式思考即可。WWARE编译器会尝试自动将代码从同步转化为异步。业务代码先经过编译器生成AST(抽象语法树),然后在AST的基础上按照变量影响范围,自动将代码分组,每个分组的代码是原子的(Atomic Block)——只需要在开始和结束同步一次代码,中间无需考虑同步。这个模型类似javascript里的worker,opencl里的thread。最终在目标平台运行的程序将是完全异步的,从而带来了指数级的性能提升。按照目前的需求,WWARE编译创建的代码,主要是针对IO执行异步,不针对重计算执行异步。如果需要重计算的应用场合,请自行书写异步代码,WWARE的编译结果是针对IO请求优化的。
2. NGINX服务器:
我们的Web server。采用的是基于异步模型的Nginx。并在其标准包里,添加了如下模块:
- 内存缓冲
- 缓冲刷新
- 面向浏览器的动态优化
- 链接热迁移
3. Web controller:
业务逻辑层,我们采用了Node.js。以javascript来书写代码,并且代码无需考虑异步,无需考虑状态,在发布时,对代码执行编译,正确处理其异步模型以及资源消耗,stateful等等话题,因此,WWARE环境下,服务器业务逻辑代码会比传统的客户端代码还要简单——其实,在wware开发环境下,大多数情况下,是不需要动代码的。
4. 集群维护协议:
对于一个数据中心的集群内敏感数据(consensus data), 我们采用etcd来同步。对于多数据中心之间的敏感数据,由于etcd所支持的raft协议,要求低延迟的稳定网络环境,不适合做数据中心之间的敏感数据同步。因此,多数据中心之间的数据同步,我们采用了支持gossip协议的serf来维护。
5. 多数据中心的设计目标:
对于多数据中心,我们的设计目标是分布系统,而不是冗余或者基于同步的性能。换言之,每个数据中心处理的数据是不同的——只有其中很少一个部分需要同步。整个调度中心位于客户端,由客户端根据用户需求驱动分布。这个模型可以非常好的解决并发访问上限的问题。无论多少并发,只要系统规模足够大,永远不会有延迟现象。
现在很多系统的规模受制于单数据中心。例如国内的铁路订票系统12306,对于单数据中心而言,技术已经很不错的。但是单数据中心的硬件限制摆在那里,当海量并发发生时,这个单数据中心总有无法承受的极限。而WWARE将其分布起来,由没有上限的数据中心来处理,理论上,并发的限制会消失。
因此,WWARE的多数据中心并不能取代异地备份,它的设计目标是为分布系统服务的,是解决海量用户并发问题的。
五、关于存储类型
目前各类存储各有优缺点,wware将其分为五类,分别加以利用。
1. 文件存储:用于存储文件类资源。文件存储只需要兼容posix规范即可,可以挂载到本地文件系统的共享存储即可。因此,CEPH,glusterfs,NFS都可以被无缝集成进入wware。
2. 内存存储:数据获取的延迟(对磁盘而言主要是寻道时间),HDD在10ms级,SDD在100us级,而DDR3-2666内存可以进入800ps级别。相差100,000-10,000,000倍。因此,集群内部各节点,使用内存存储来存储热点数据。当前,wware使用的内存存储为REDIS集群,并做了适当修正,用于支持热点迁移。所谓热点迁移,是因为网络也是有延时的,如果配置没有问题,电口网络的延时,通常在50微秒级别,而光口网络的延时,会比电口快(随距离加大,光口优势逐步增加),但是与内存的速度差距依然在万倍以上。因此,WWARE支持了热点迁移,也就是一个数据被当做热点使用时,直接缓冲在本地,更新方会主动通知刷新缓冲。正是因为这些细节的优化,应用在WWARE集群环境中执行,会比不注意IO性能的单机应用还要快很多倍——对于很多APP,我们实现的相同功能的页面,从网络加载的速度会超越APP的本地打开速度。(APP与网页的区别,1%是为了打破浏览器沙盒,99%是为了减少网络加载,从而提升性能)。
3. 全文检索: wware的全文检索引擎采用了基于lucene的elasticsearch。
Elasticsearch是分布式的。不需要其他组件,分发是实时的,被叫做”Push replication”。
Elasticsearch 完全支持 Apache Lucene 的接近实时的搜索。
处理多租户(multitenancy)不需要特殊配置,而Solr则需要更多的高级设置。
Elasticsearch 采用 Gateway 的概念,使得完备份更加简单。
各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作4. 事务数据库:
由于全文检索缺乏事务(Transaction)支持,因此,wware引入了事物数据库来支持这一特性。目前wware采用的是Postgresql。我们选择Postgresql的原因如下:
PostgreSQL完全免费,而且是BSD协议。PostgreSQL的社区非常庞大,使其经历了大量的测试,确保了性能与稳定。
与PostgreSQl配合的开源软件很多,有很多分布式集群软件,如pgpool、pgcluster、slony、plploxy等等,很容易做读写分离、负载均衡、数据水平拆分等方案。
PostgreSQL源代码结构清晰,易读性好。这增加了其维护性。国产数据库基本都是在PostgreSQL基础上封装而来。当然,你可以使用Mysql,Oracle,Sql Server等其它数据库。但是此时您需要自己注意全索引状态,wware没有测试创建的代码,在其它数据库下是否是全索引状态。
wware的全索引支持,是为了保障检索速度与规模无关。换言之,一条数据与百亿条数据的检索速度几乎是一致的。实际上,无论传统数据库还是全文检索,如果确保检索条件最终都能正确利用索引(bitmap,btree,hash,rtree,lsm...)。那么,其检索效率遵循Hash的检索效率,为固定常数——微小变化来自于范围扩大引发的计算扩大,再加上bulk支持,更可以消除数据增加引发的额外计算时间增加。传统上,检索与数据规模有关,通常原因是设计的检索语句并没有配置为全索引状态。如果利用wware自己的检索生成器,那么wware会同时修改索引配置,确保检索语句全部命中合适索引。
当然,实践中,也有很多聚合计算类的需求,聚合计算是严格的数据规模线性相关的。WWARE尝试生成合适的存储过程,将聚合类计算分发到所有的集群节点,以提升性能。但是,聚合类需求依然是数据规模相关的,处理千万、亿级的数据就很吃力了——除非使用大规模集群来缓解。因此,产品设计中,如果有可能,应该规避聚合类需求。如果聚合需求不可避免,并且规模庞大,需要构建合适的诸如MapReduce之类的机制来解决,典型的可以使用Hadoop,Apache spark,这些都可以很方便的被wware所集成。
5. 外部存储
有很多外部的网盘,云盘,乃至出于异地备份而自己构建的外部存储,可以被wware利用。wware暴露了一组API,需要自行实现这组API来支持外部存储。现在,wware尚未支持任何的外部存储。
六、任务执行
web controller作为一个热点——调度中心也意味着指挥中心。应该集中全部精力去执行调度的职责。因此,需要消耗系统资源的事情,例如邮件发送,短息通知等,被wware以任务的形式调度到专用的任务执行器上去执行,从而降低调度中心的工作量。从代码角度来看,执行器拥有与调度器相同的执行环境。wware目前不支持自动分拆及迁移任务,但是roadmap中已经有了这一特性。正是因为执行器的存在,controller可以获得更高的并发性。由于任务可以通过网关调度到其它环境下执行——极端的例子,可以通过internet,把高耗时的任务(例如渲染,科学计算,物理模拟等)放到民用环境下利用特殊计算机(例如专用的FPGA,需要水冷的显卡集群)执行,从而极大的提升整个系统的吞吐量。
任务分发,目前wware采用的是RabbitMQ集群。如果使用其它Message Broker,需要实现wware的相应接口。
我们采用RabbitMQ来做job的调度服务器。用于集群间任务的调度。
集群部署与维护:
目前wware的集群部署采用ansible方案。没有使用puppet,chef。
关于:中科研拓
深圳市中科研拓科技有限公司专注提供软件外包、app开发、智能硬件开发、O2O电商平台、手机应用程序、大数据系统、物联网项目等开发外包服务,十年研发经验,上百成功案例,中科院软件外包合作企业。通过IT技术实现创造客户和社会的价值,致力于为用户提供很好的软件解决方案。联系电话400-0316-532,邮箱sales@zhongkerd.com,网址www.zhongkerd.com
- 上一篇 [返回首页] [打印] [返回上页] 下一篇