银行系统软件架构的发展趋势:全面拥抱开源去IOE化
- 2016-03-14 09:31:04
-
我自06年开始做兼职,就一直在金融行业,更准确地说,一直在银行业。这样的经历是幸运的,也是比较悲催的。悲催的是,基本上只懂银行,而且银行IT的压力比较大。幸运的是,银行在信息化建设中是前沿行业,同时要求高,所以也呆过很多不错团队,见到过很多比较好的东西。
今天的分享主要是基于我最近的工作,基于自主可控技术的新一代银行架构,来看银行这个领域的一些架构特点。
首先,为什么把基于自主可控技术的架构称为新一代架构?这里说的新一代本身并不是指采用了像“量子计算”这样的前沿技术的架构。这里的“新一代”是相对于当前银行业的主流的“IOE”架构而 言的。“IOE”指代的是由以IBM、ORACLE和EMC(被收购之前)为代表的商业解决方案。这些解决方案对于银行来说,是一个黑盒子,无法自主掌 握。一切的开发、运维均需要服务商的支持与协助。而新一代的基于自主可控技术的银行架构,则更多的选择开放性的技术平台以及开源的技术产品,例如 XML:X86框架的PC服务器、MySQL为代表的开源数据库和LINUX为代表的开源操作系统。是的,没什么了不起的技术,但是从来没有哪个银行把一 家银行的架构完完全全地交给XML来构建。
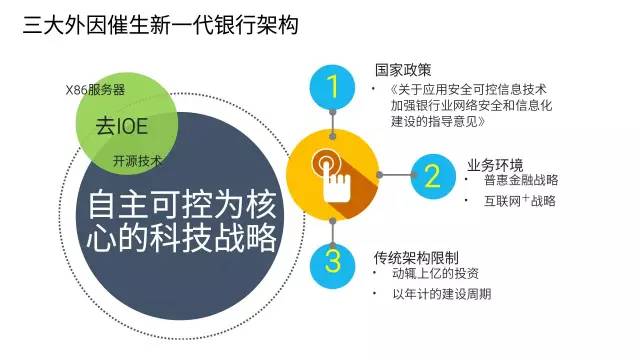
既然从来没有发生过,那么为什么突然想要去做呢?三大外因驱动新一代银行架构的诞生。
-
从国家层面,尤其是“棱镜门”曝光之后,相关监管机构推出了著名的“39号文”: 《关于应用安全可控信息技术加强银行业网络安全和信息化建设的指导意见》。无论后续的发展被解读为“叫停”、“暂停”,国家鼓励在银行也推动自主可控技术的应用已经是一个明确的方向。
-
其次,从行业发展的角度,银行从依托对公及高净值个人客户,依靠利差为主要收入来源的“躺着赚钱时代”逐步步入了“以客户为中心,通过场景服务更多人群”的“互联网+”战略下的普惠金融时代。而传统架构下,居高不下的成本是一个巨大的障碍。
-
最后,传统架构的双高也是很多新兴金融机构所无法接受的:“资金成本高”和“时间成本高”。
因此,寻求基于自主可控技术的架构,几乎是新一代架构的必然选择。
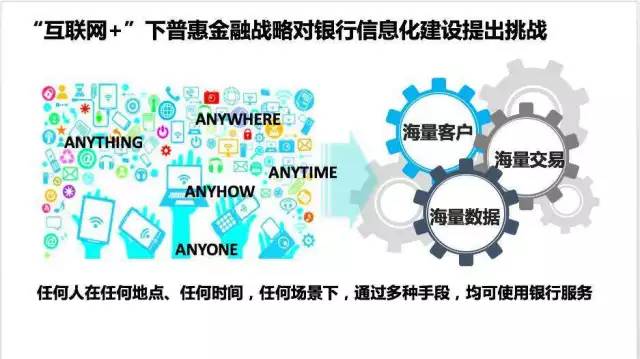
在业务形态上,互联网银行往往有以下一些特点:“纯线上、轻人力、强系统”。因此,互联网作为这些机构唯一的客户触点,完全打破了所有已知的银行运营模式。一个看似简单的远景:“任何人在任何地点、任何时间、任何场景下,通过多种手段均可使用银行服务”,同时这也令新一代架构站在了海量挑战的风口浪尖:源源不断的来自各个不同阶层、不同背景的海量客户,随之而来的海量交易以及需要处理于存储的海量数据。而这一切,成为了新一代银行架构从第一天起就不断研究、解算的命题。
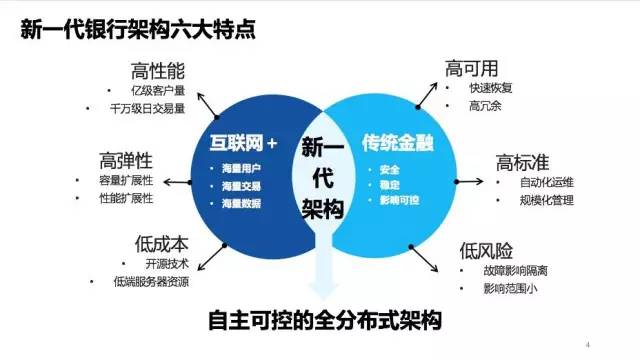
这道命题的答题思路被总结成了8个字“融合创新、平衡互补”。融合什么?融合互联网和银行。互补什么?以银行IT的诉求和互联网技术之间形成互补。简单来说,新一代需要在做到互联网行业所擅长的“高性能、高弹性和低成本”的同时,保持传统金融行业对于“高可用、高标准和低风险”的追求。
之前看到一篇文章,忘记作者是哪位大咖(诚惶诚恐。。。),其中有一段话记忆尤为深刻。在“如何称为一个合格的架构师”这个章节下,大咖提出了四门必修课,其中一门是“能和稀泥”。这“和稀泥”其实是指一个妥协的过程。而我个人的理解是:架构没有很好的,最正确的,只有最合适的。按最合适的方式,在最合适的时间点,以最合适的成本获得一个可能获得的很好的结果。这个就是架构师要做的。
为什么说这些呢?因为大家肯定已经看到了,要融合银行和互联网,难度不亚于要让油溶于水。那么,这里面很重要的一点就是如何在不同的场景下,对架构设计进行取舍。
诚然,很多时候的讨论都是case by case并且激烈的。但是,一个核心价值逐渐成为主导性因素:业务连续性。首先,它是监管机构悬在所有金融机构头顶的利剑。其次,它是一个金融机构的信誉所在。业务连续性的两个主要考核指标:RPO和RTO,一个决定了金融业务的安全性,一个决定了业务的可用性。老百姓不会相信一个动不动丢数据或者动不动因为市政工程就停业务的金融机构。然而,单点的可用性和稳定性往往是XML(重要事情再说一遍:XML指代新一代自主可控技术的主要代表:X86服务器、MySQL数据库和LINUX操作系统)的短板。
因此,我们围绕着构成整个架构的4个关键底层资源,做了很多工作来保证业务连续性。在必要的时候,我们会舍弃单点的性能和灵活性,来保证业务连续性。例如,在数据库网关上进行QPS的限制,将数据库的负载在一个合理的范围,确保分布式数据库中存储相同数据的多个副本的多个节点间的数据同步的强一致性。那么性能怎么办呢?一个节点被限制了,那么通过逻辑将数据进行分布,用更多的节点来承载业务,聚沙成塔。

如何聚沙成塔?如何在金融行业构建一个全分布式架构?一种实践解决方案是以客户为单位进行数据分布。以我熟悉的银行业为例,具体来看:将银行的所有服务功能分成了两大类:对客户服务和后台管理服务。所有对客服务的能力,按照分布式架构设计理念,构建了多个服务相同类型客户的数据中心节点,DCN。每个DCN承载一个独立的客户群体,拥有服务这个客群的所有能力以及属于这个客群的每个客户的所有数据。
而熟悉银行业务的老师们可能会指出,很多银行的关键数据是要以整个银行作为整体来看的,例如:会计科目的余额、授信额度和理财产品销售额度等。确实如此,针对处理此类数据的后台管理服务,可以采用集中部署的方式,实现对全行的数据处理的支撑。分布式架构不适合这样的业务处理场景。因此,这部分系统可以采用集中部署,通过其他的分布式技术、可无限扩展的计算集群以及可按功能拆分的应用架构,最终实现对这个节点的加固。

前面讲的是自主可控架构的一种逻辑实现。在技术组建的规划和选择上,也有一些特殊的考虑。在我自己的实践过程中,不知不觉地实践了MVP(minimum viable product)和极简主义。之所以说不知不觉,是因为在一开始的时候,我们并没有明确地提出这两个观点作为架构基本法。极简主义的一些理念在讨论中浮现过,而MVP则并没有被提及。但是,最后,我们发现,即使是底层架构这种相对较硬,灵活性较差的事物,依然可以通过MVP这种强调快速迭代的方式来规划建设。期间有很多挫折,也走了很多弯路。
但恰恰是MVP这种理念,使得我们最终能以较小的代价摸索出一条并无太多可借鉴的架构建设道路。至于极简主义,则是刻意的让每个组件只做一件事情,避免使用一个过于复杂,功能过于强大的“平台”。这个架构不能有明显的“死穴”。其实想想,这个做法更像《失控》里面描述的“Subsumption Architecture”。
-
Do simple things first.
-
Learn to do them flawlessly.
-
Add new layers of activity over the results of the simple tasks.
-
Don't change the simple things.
-
Make the new layers work as flawlessly as the simple.
-
Repeat, ad infinitum.
这种实践其实最终和MVP理念浑然一体。

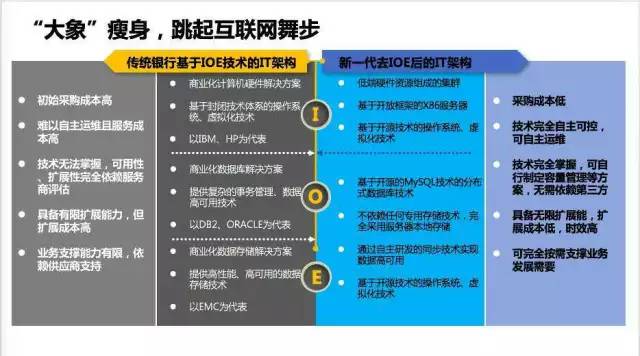
讲了这么多,附上一张对比图,对比的是传统IOE架构和新一代的XML架构。图上的内容很多,这里就不冗余述。
精彩问答 问题:全文围绕可控做了精彩论述,但去IOE成本着实不小,如何衡量value?
这个问题非常好,去IOE非常难。做到需要很全面的技术储备。如果没有,则从短期来看,投入和成本都非常高。但是,从长远上看,确实很明显。单账户的一年的IT成本,可以轻松的达到同业的零头。
问题:想问一下,xml中,对核心账务部分怎么处理的?
这个问题貌似和基础架构关系不大,我试着回答一下哈(之前也做过几年核心,呵呵)。核心的账务分成分户帐和总账两部分处理。分户在每个客户节点,总账在后台管理节点。分户完成余额之后,异步送总账核心拆分录和记账。因为是异步的,所以不怕多打一。
问题:每个DCN承载着独立的客户群,这个客户群是按什么划分的?
随机分布,希望借此达到各个节点的客户行为基本类似,而不希望因为某些属性,导致某类客户过度集中,使得节点的负载差异太大
问题:那张“以客户为单位的全分布式架构总览”图中,客户端节点1到N之间的“数据备份”是通过什么技术实现的?备份的频率?
那张图是当前1.0架构的情况:每个节点有一个主节点,一个同城备节点和一个异地备节点,主备间都是异步同步。将要实施完成的2.0架构下,同城将打通成一个多活集群,但和异地备节点的备份还是异步同步。备份是实时的,异步场景下,同城时延的P95是差不多2-3秒,异地也差不多(多的仅仅网络传输部分,几十毫秒吧)。
问题:想问下有没有遇到架构扩展性不太好的事情,后面怎么解决?
整个架构里面,最硬的是IDC和网络,这两部分确实遇到了使用速度远高于规划容量的问题。这里面,IP的规划上我们吃了些亏,目前IP吃紧,限制了一些更高虚拟比的应用场景。所以,这块大家如果做的话,需要充分评估好自己的集群规模,否则一旦投入生产,要加IP就会比较麻烦。
问题:架构合适就好,但是可扩展这个怎么把控呢?
这个问题非常好,架构基本法里面会规定横向扩容和纵向扩容的策略,定期review相关的阀值,有一组数据模型来进行相关的容量管理和规划。基本上:横向扩容解决客户容量问题,纵向扩容解决存量客户性能问题(性能包括APP服务器的性能,和DB的容量和性能)。
问题:之前的IOE时,项目进度是如何管理,代码行?功能点?还是其他呢?在新的公司,这方面又是如何管理呢?有什么相同与不同呢?
个人认为项目管理和架构并没有太大的关系。过去在IOE架构下的金融机构,一般是比较标准的瀑布式。现在的团队是敏捷+持续集成,依托一个比较灵活的灰度机制,可以做到核心应用发布常态化,这样需求就能切分的比较细。(这个可能需要我们的开发团队的同学来回答会更准确些)
问题:数据中心节点是按照客户划分的,但一般金融机构都有自己的业务管理机构,客户分属不同的机构,这样如果按照业务管理机构去做一些事情,就存在跨节点的操作了。不知道微众银行存不存在这方面的问题。
业务上不存在分支机构,所以不存在您说的那种场景。但是存在跨节点交易,例如转账的收付双方可能在两个不同的节点上。这个时候就需要由发起方负责整个事务的一致性(采用的还是之前的说的补偿的机制)。
问题:DCN客户如果是随机划分,怎么做的数据路由(根据用户什么值做的路由),算法是一致性哈希么?是否用过分库的中间件产品?银行业务在oralce中有大量的过程,在转到mysql都进行了剔除了么?
数据路由是通过一个客户定位组件来实现的一个基于内存KV的lookup。然后把节点信息填入消息的报文头,然后消息总线会完成路由。(一致性哈希算法用在了对内存KV的分片上,路由本身不需要算法,就是依赖高速查询来实现)存储过程必须统统干掉,我们的数据库不支持。我们的数据库支持分库分表。
问题:如果采用XML架构,这里所说的“每个DCN是随机分布的”,是采取什么技术方式实现随机分布的呢?
逻辑上是在每个客户注册的时候,由一个公共组件负责分配她/她到某个节点上,算法也比较简单:加权的RR。加权主要是为了实现在一些特殊的客户分流需要,例如:通过特地调低一个节点的权重,使得的它的用户数比较少,可以用来灰度发布。
问题:去IOE是个困难的过程,但是在去IOE的过度时期怎么把握新架构系统和老系统的共存?
这个过渡时期确实困难, 异构系统之间因为架构的差异性,只能通过服务化的框架来解藕。并且通过队列、缓存等机制来实现两者之间的一个缓冲与保护(柔性设计)。如果做不到这些,问题会很多。在我们的场景下,因为没有旧系统,所以,我还没有失业。
嘉宾介绍 李靖,2007年加入Merrill Lynch FICC(Global),开始了自己的银行IT之路。从事Merrill Lynch FX Trading Platform开发工作。期间完成了自动化集成测试模块以及风险评估模块等功能的开发设计工作。2009年,回国加入厦门国际银行,全面参与了国内商业银行相关应用系统的设计及开发工作,涉及核心系统、支付清算平台以及柜面系统等银行主要应用。
2010年加入英华达科技,负责金融服务事业部。期间作为项目经理及主架构师,主导了包括广发银行,海峡银行以及乌鲁木齐商业银行在内的多家国内商业银行的核心系统升级替换、整体IT架构规划以及企业级IT架构治理的工作。
2014年加入微众银行,目前是微众银行科技事业部基础架构产品部架构师,全面参与全行IT基础架构的规划设计工作,设计并实施了微众银行基于自主可控技术的分布式基础架构。
关于:中科研拓
深圳市中科研拓科技有限公司专注提供软件外包、app开发、智能硬件开发、O2O电商平台、手机应用程序、大数据系统、物联网项目等开发外包服务,十年研发经验,上百成功案例,中科院软件外包合作企业。通过IT技术实现创造客户和社会的价值,致力于为用户提供很好的软件解决方案。联系电话400-0316-532,邮箱sales@zhongkerd.com,网址www.zhongkerd.com
-
- 上一篇 [返回首页] [打印] [返回上页] 下一篇